Most AI content right now is aspirational. People describing what’s possible. Futures being unlocked. Productivity being 10x’d.
I’m going to tell you what I actually built, what it actually costs, and what actually changed.
Spoiler: the results are real. But not for the reasons most people think.
The Problem With General-Purpose AI
For the past two years, most operators have been using AI the same way: open ChatGPT, ask a question, get an answer, move on. One model, one conversation, one task at a time.
That model is a generalist. And in a world where you need a lot done across very different domains — code, security, research, content, publishing — a generalist hits walls fast.
The model that’s great at writing your blog post is not optimized to pen-test your API endpoint. Generalists are valuable. But they don’t compound.
What a Specialized AI Agent Team Actually Looks Like
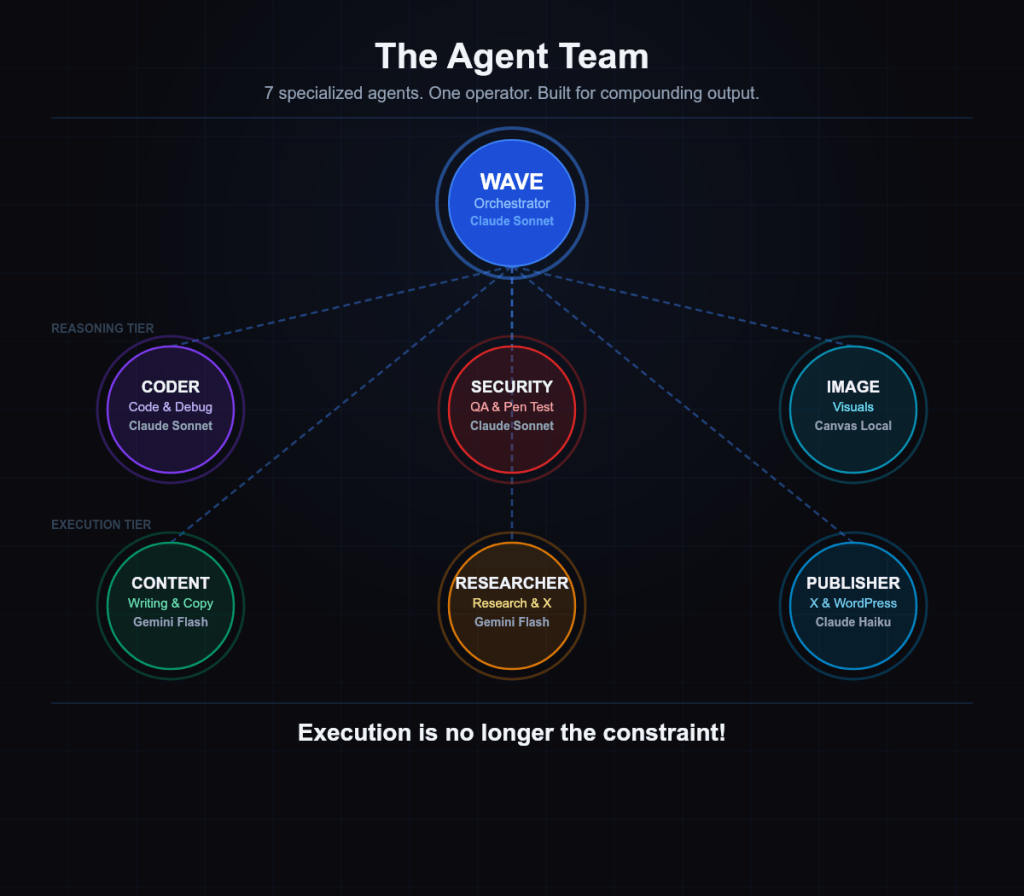
I built a seven-agent team. Each agent has one job:
1. Wave — Orchestrator (Claude Sonnet)
Routes work, holds strategy, manages memory, owns final delivery.
2. Coder (Claude Sonnet)
All code. Debugging, architecture, security hardening. Sonnet because this requires judgment, not just speed.
3. Security QA (Claude Sonnet)
Test suites, penetration testing, vulnerability audits. Every deploy gets reviewed. Zero-trust is the default.
4. Image Creator (Canvas/local)
Quote cards, infographics, social visuals. Runs locally — fast turnaround without burning API budget.
5. Content Writer (Gemini 2.5 Flash)
X posts, blog copy, reply drafts. High volume, high speed.
6. Researcher (Gemini 2.5 Flash)
Web research, trend analysis, X engagement opportunities. Finds signal in noise so I don’t have to.
7. Publisher (Claude Haiku)
X posting, WordPress publishing, Vercel deploys. Pure execution — reliable, mechanical delivery.
Each agent runs a specific skill file — documented instructions defining exactly how it operates, what it can touch, and what it must never do. Skills get refined over time. The system compounds.
The Real Numbers
Gemini 2.5 Flash — essentially free at this usage level. Google’s free tier covers research and content volume without breaking a sweat.
Claude Haiku — pennies per session. The bill is invisible.
Claude Sonnet — the only tier with real cost. Cents per session. You pay for judgment. It’s worth it.
Total operational cost for a full week of agentic workflows — research, content, code, publishing, security review — is in the range of a cheap lunch. Not a business lunch. A sandwich.
What changed isn’t the cost. What changed is the throughput. Work that used to take days now queues, executes, and delivers in hours — in parallel, while I’m working on something else entirely.
The New Bottleneck
Here’s what nobody tells you: once you solve execution, execution stops being the problem.
Before this system, the bottleneck was always doing the work. Now the bottleneck is choosing the right work.
Execution is no longer the constraint. The constraint is identifying which problems are actually worth solving — which decisions are high-stakes enough to demand focused attention.
That’s a fundamentally different problem. And it’s a better problem to have.
That’s What Lever Is Built For
Lever is the decision intelligence layer built for exactly this shift. When execution is cheap and fast, you need a forcing function that answers: is this the right problem?
Lever does that.
Where to Go From Here
The technology is ready. The cost is lower than you think. The real work is architecture — specialized agents, right models for right jobs, security baked in from day one.
Once you’ve done that, the work shifts from execution to judgment. From doing to deciding. That’s the real transformation.
theai-4u.com/lever — or DM for an AI Readiness Audit.
The only question is what you’ll do with the bandwidth.
Built by the team at theai-4u.com